 Tech Gadget Central Latest Tech News and Reviews
Tech Gadget Central Latest Tech News and Reviews

Artists and AI companies continue to fight in court.
In recent months, several lawsuits have been filed against OpenAI and Stability AI over their generative AI tech, alleging that copyrighted data, mostly art, was used to train the models without permission. Generative AI models “train” on random web images and text to create art, code, and more.
Jordan Meyer and Mathew Dryhurst founded Spawning AI to give artists more control over how their art is used. Spawning created HaveIBeenTrained, a website that lets creators opt out of Stable Diffusion v3’s training data set.
Artists used HaveIBeenTrained to remove 80 million works from the Stable Diffusion training set by March. By late April, it exceeded 1 billion.
The bootstrapped Spawning sought outside investment as demand for its service grew. Got it. Today, Spawning announced a $3 million seed round led by True Ventures with Seed Club Ventures, Abhay Parasnis, Charles Songhurst, Balaji Srinivisan, Jacob.eth, and Noise DAO.
Meyer told via email that the funding will allow Spawning to develop “IP standards for the AI era” and stronger opt-out and opt-in standards.
We love AI tooling. “We developed domain expertise in the field from being passionate about new AI opportunities for creators, but feel that consent is a fundamental layer to make these developments something everyone can feel good about,” Meyer said.
Spawning metrics are clear. Artists want more control over how their work is used (or scrapped). Spawning hasn’t united the industry around an opt-out or provenance standard beyond partnerships with Shutterstock and ArtStation.
Adobe is developing opt-out tools for its generative AI tools. DeviantArt launched an HTML tag-based protection in November to prevent image-crawling software robots from downloading images for training sets. OpenAI, the room’s generative AI giant, doesn’t have an opt-out tool and doesn’t plan to.
Spawning has also been criticized for its unclear opt-out process. According to Ars Technica, the opt-out process doesn’t appear to meet Europe’s General Data Protection Regulation’s definition of consent for personal data use, which requires active consent, not default consent. How Spawning will legally verify artists’ opt-out requests is unclear.
Spawning has multiple approaches. First, it will simplify opt-out requests for AI model trainers and creators. Meyer says Spawning will then provide more artist protection services to organizations.
“We want to build the consent layer for AI,” he said. “Spawning will grow to serve the many domains touched by the AI economy, as each domain has its own needs.”
In March, Spawning enabled “domain opt-outs,” letting creators and content partners quickly remove content from entire websites. Spawning has registered 30,000 domains.
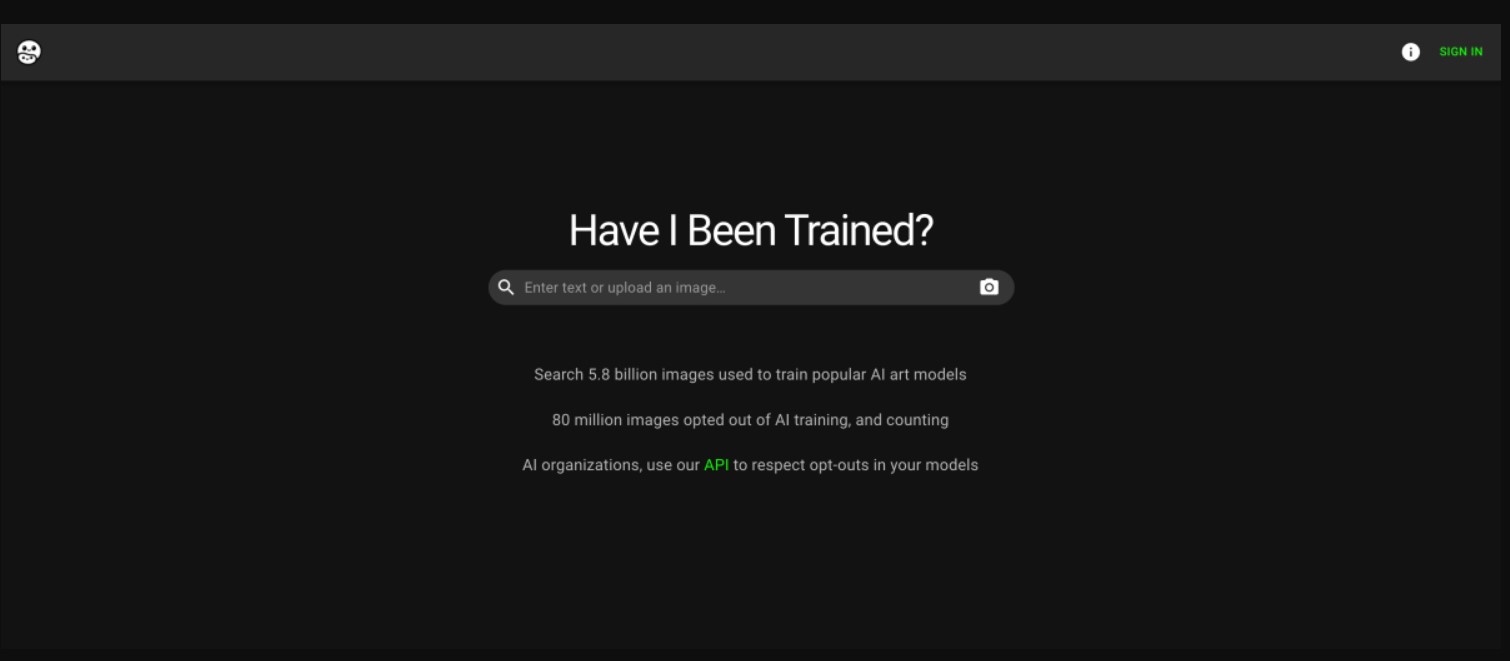
An API and open-source Python package will greatly expand Spawning’s content in April. Opt-out requests through Spawning previously only applied to the LAION-5B data set, which trains Stable Diffusion. Any website, app, or service can use Spawning’s API to automatically comply with opt-outs for image, text, audio, video, and more starting in April.
Meyer says Spawning will aggregate every new opt-out method (e.g., Adobe’s and DeviantArt’s) into its Python package for model trainers to reduce the number of accounts model creators must manage to comply with opt-out requests.
To increase visibility, Spawning is partnering with Hugging Face, one of the largest platforms for hosting and running AI models, to add a new info box on Hugging Face that will alert users to the proportion of “opted-out” data in text-to-image data sets. Model trainers can remove opted-out images at training time by signing up for Spawning API through the box.
“We feel that once companies and developers know that the option to honor creator wishes is available, there is little reason not to,” Meyer said. “We are excited about generative AI, but creators and organizations need standards to make their data work for them.”
Spawning plans to release a “exact-duplicate” detection feature to match opted-out images with web copies, followed by a “near-duplicate” detection feature to notify artists when Spawning finds likely copies of their work that have been cropped, compressed, or otherwise slightly modified.
A Chrome extension to let creators pre-emptively opt out of their work being posted anywhere on the web and a caption search on the HaveIBeenTrained website to directly search image descriptions are also planned. The site’s search tool only searches URLs and approximate text-image matches.
Meyer wouldn’t say how Spawning, now owned by investors, plans to make money by building services on its content infrastructure. Content creators’ reactions are unknown.
Meyer said, “We’ve spoken to quite a few organizations, with many conversations being too premature to announce, and think that our funding announcement and increased visibility will go some way to offer assurances that what we are building is a robust and dependable standard to work with. “After we finish these features, we’ll build infrastructure to support more datasets—including music, video, and text.”


